
整理 | Jane
出品 | AI科技大本营(id:rgznai100)
【导读】6 月 16--20 日,计算机视觉与模式识别领域顶会 CVPR 2019 在美国长滩举行。每年的 CVPR 盛会除了精彩的论文分享、Workshop 与 Tutorial,还会举办多场涵盖计算机视觉各子领域的专项比赛,竞争亦是非常激烈。在此次人体姿态估计和人体分割比赛中,字节跳动的两个团队榜上有名,收获两个冠军、一个亚军。
关于 LIP 竞赛
“Look Into Person”(以下简称 LIP )国际竞赛拥有大规模的人体姿态图像数据库、公平严格的评审标准以及国际性的竞赛影响力。本届 LIP 国际竞赛吸引了超过 75 支队伍参加,包括加州伯克利大学、NHN、悉尼科技大学、东南大学、上海交通大学、中国电子科技大学、香港中文大学等全球高校以及三星、字节跳动、百度、京东等科技企业的人工智能研究院机构;包括五个竞赛任务,分别是:
单人人体解析分割( the single-person human parsing)
单人人体姿态估计( the single-person pose estimation)
多人人体解析(the multi-person human parsing)
基于视频的多人人体解析(multi-person video parsing, multi-person pose estimation benchmark)
基于图像的服装试穿(clothes virtual try-on benchmark)
今年的 LIP 国际竞赛上,字节跳动人工智能实验室拿下了两个国际冠军和一个国际亚军。由字节跳动和东南大学组成的团队、以及肖斌带领的字节跳动团队并列单人人体姿态估计比赛的国际冠军;同时,字节跳动和东南大学组成的团队同时还获得了单人人体分割赛道的国际亚军。

在单人人体姿态估计比赛中,两个队伍都刷新了去年的最好成绩。其中,由字节跳动和东南大学组成的团队提出了基于增强通道和空间信息的人体姿态估计网络,参考 CVPR 2019 论文《Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information》。
传送门:
https://arxiv.org/abs/1905.03466
肖斌团队则提出利用高分辨率网络(HRNet)来解决人体姿态估计问题,参考 CVPR 2019 论文《Deep High-Resolution Representation Learning for Human Pose Estimation》。目前该论文的算法已经在 Gituhub 上开源,放地址:
传送门:
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
下面为大家详细介绍两支冠军团队的工作。
技术解读(一)

字节跳动和东南大学组成的团队提出了基于增强通道和空间信息的人体姿态估计网络,论文《Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information》的一作苏凯是来自东南大学模式识别与挖掘实验室(PALM)硕士生三年级,师从东南大学耿新教授。目前在字节跳动人工智能实验室实习,导师是喻冬东博士(共同一作)和王长虎博士。
介绍
人体姿态估计旨在定位出图片中人的关键身体部位,例如手臂、躯干以及面部的关键点等等。对于行为识别、人体再识别等诸多计算机任务来说,人体姿态估计是一项基础且极具挑战的课题。由于人与人之间的密切交互、遮挡以及不同尺度人体等因素影响,获取准确的定位结果仍然具有困难。
创新点
首先,在卷积神经网络中,高层特征往往具有更大的感受视野,所以它们对于复杂场景下的遮挡点、不可见点的推断更有帮助。另一方面,卷积神经网络的低层特征往往具有更大的分辨率,所以它们对于关键点的精细调整更加有效。然而,在现实场景中,高低层特征之间权衡往往复杂多变。因此,论文提出通道交流模块来促进不同分辨率层特征之间的跨通道信息交流。通道交流模块的目的是通过网络自学习来校准高低层特征之间的相互补充和强化。
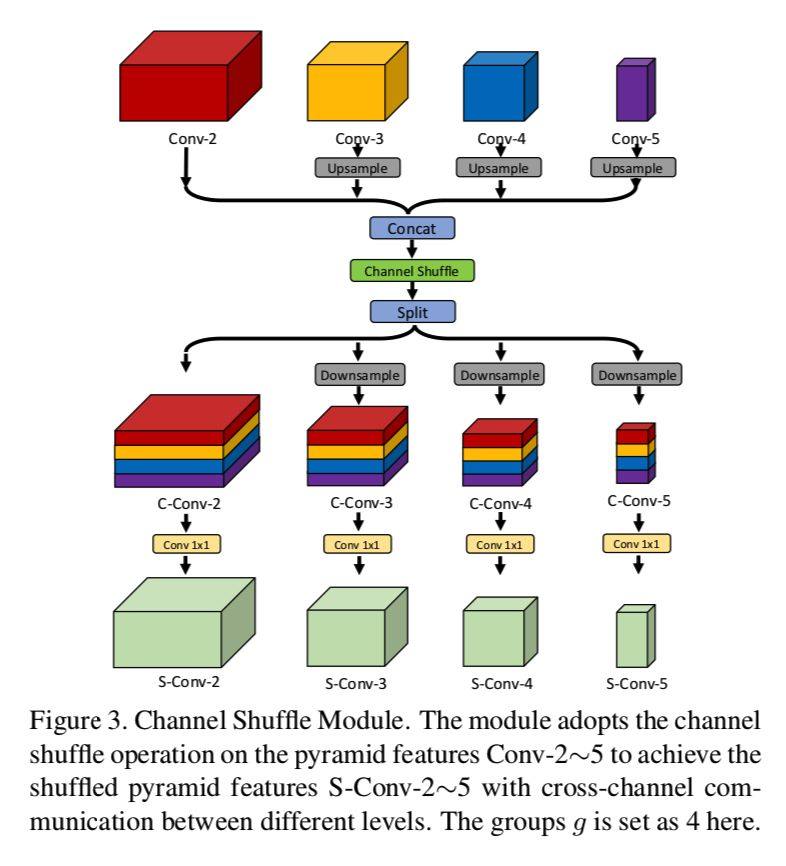
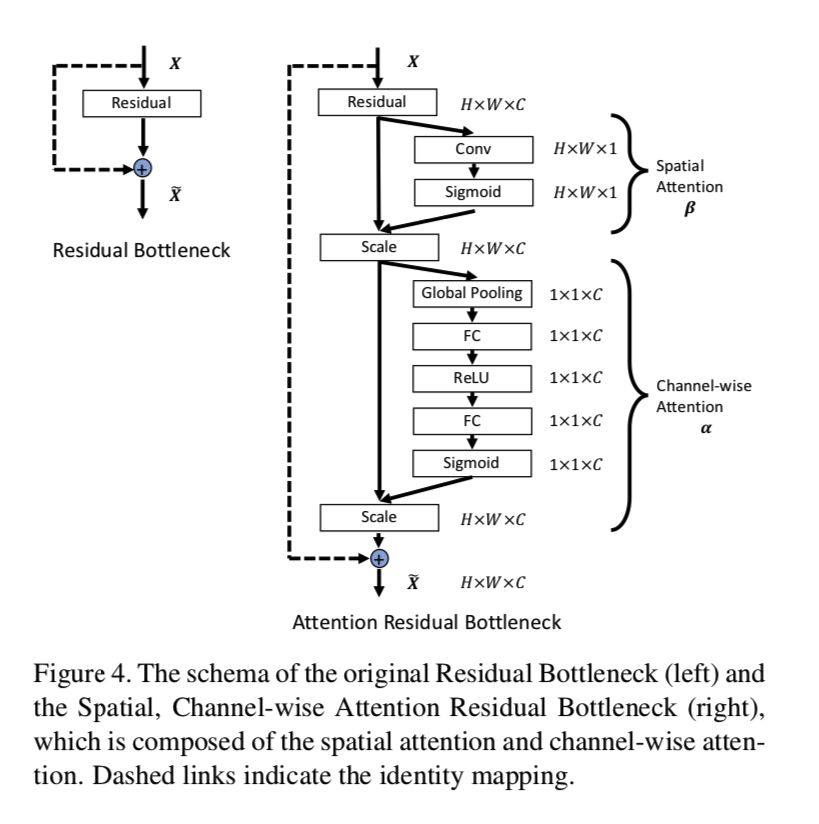
其次,特征融合的过程是动态多变的,融合后的特征往往也存在许多冗余。网络中那些对姿态估计任务更加有效的特征信息应该被自适应地突显出来。因此,论文提出基于空间和通道注意力机制的残差模块,自适应地从空间和通道两个维度增强刚刚融合后的金字塔特征信息。
实验
论文采用人体关键点检测的最权威数据集之一 MS COCO(多人人体姿态数据集)。论文的 baseline 采用 Cascaded Pyramid Network(CVPR 2018)。论文首先在 MS COCO 进行消融实验,以验证各个模块的重要性。

表3 可以看出,在只使用通道交流模块,组数设置为 4(CSM-4)的情况下,在 COCO minival 数据集的结果可以由 69.4 提升到 71.7。在只使用空间通道注意力残差模块的情况下,结果可以由 69.4 提升到 70.8。同时使用两种模块,结果进一步提升到 72.1。

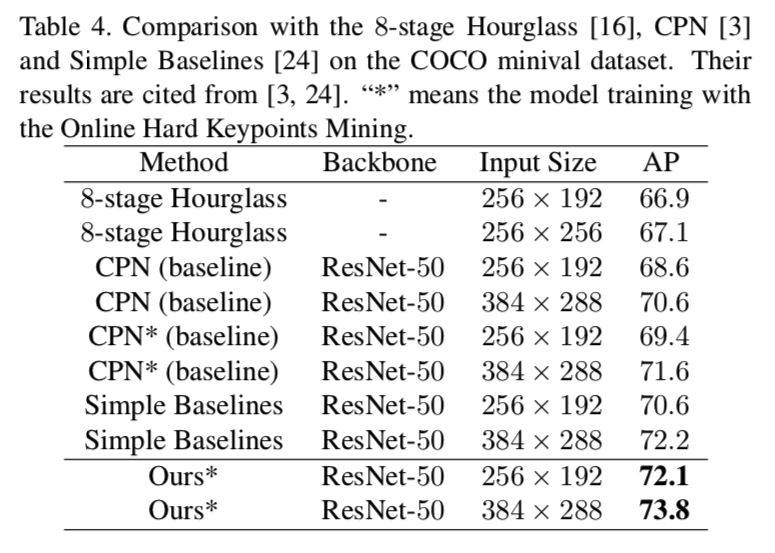
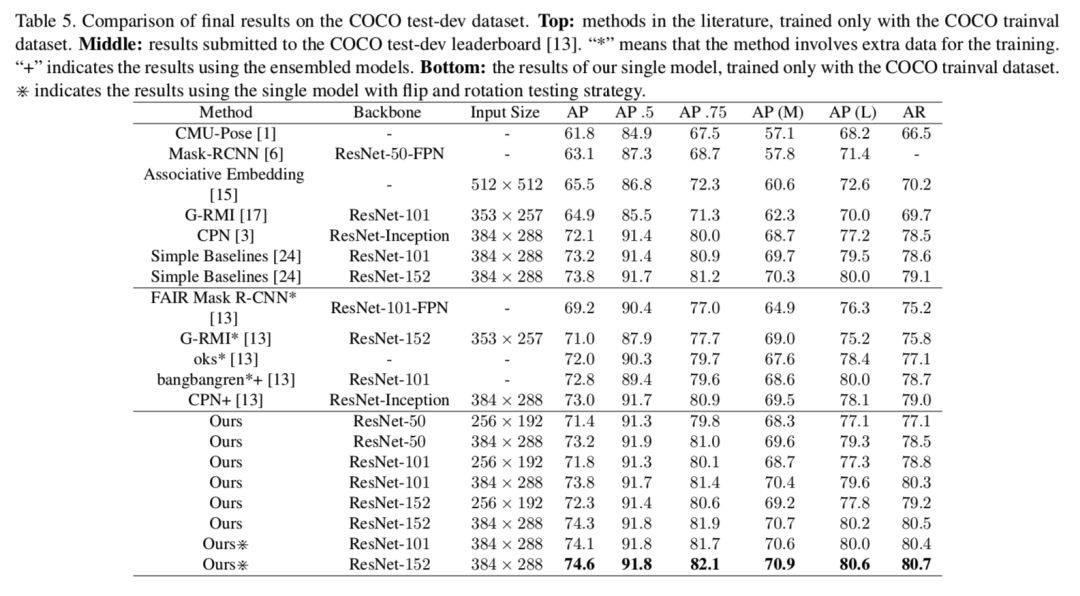
其次,论文在 COCO minival(表4)和 test-dev(表5)数据集对比了性能最先进的一些网络和结果,均取得了优异的超越。
技术解读(二)
另一个冠军队伍——肖斌带领的字节跳动团队则提出了利用高分辨率网络(HRNet)来解决人体姿态估计问题,以下是技术解读。
通用的单人体姿态识别的框架通常为:给定单人图片作为输入,通过 CNN(Convolutional Neural Network)得到高分辨率的人体关键带的热点图片,最后通过在热点图片中寻找最大极值点,得到人体关键点坐标。
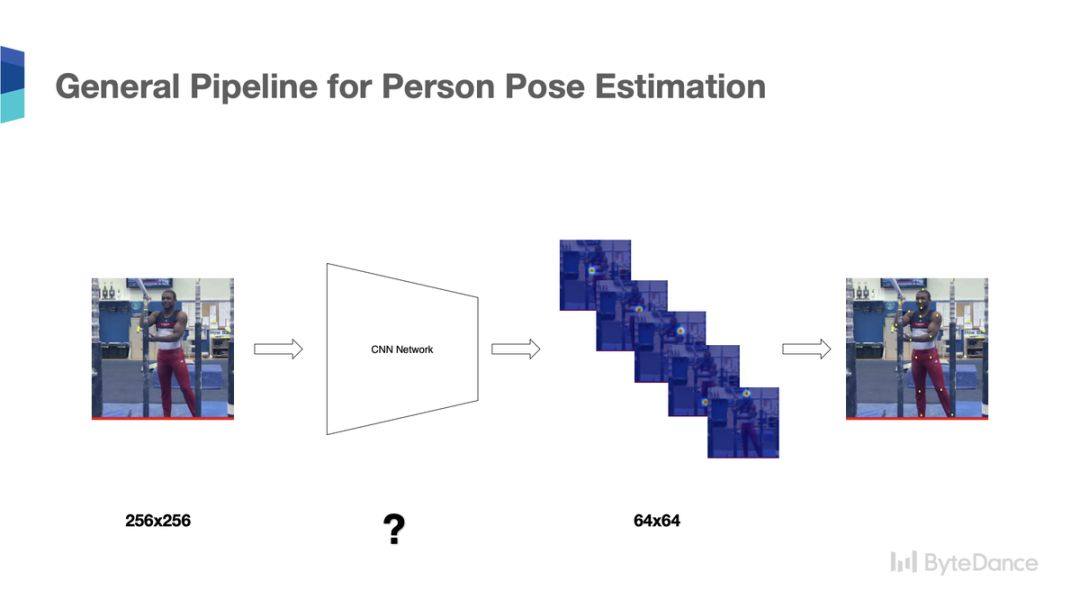
在介绍 LIP 比赛使用的 HRNet(High Resolution Network)之前,我们先回顾一下人体姿态识别常用的网路结构。
回顾常用的人体姿态识别网络
首先,先介绍一下人体姿态识别的经典网络 Stack-Houglass[1],Stack-Hourglass 由普林斯顿大学教授 Jia Deng 团队首先提出,Stack-Hourglass 网路由多个 stage 组成,每个 stage,遵循从低语义高分辨率特征图到高语义低分辨率特征图,然后由高语义低分辨率的特征图通过上采样恢复出高分辨率的特征图的串行结构,同时低语义的高分辨率的特征通过跳连结和深层的恢复的高分辨率融合。
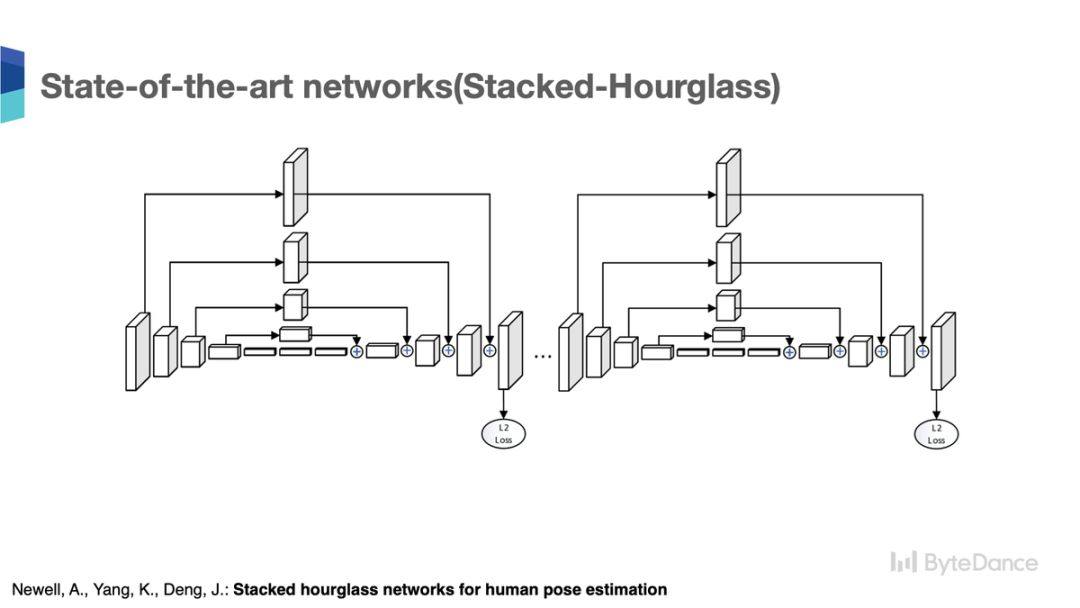
在 2018 年,COCO 人体关键点比赛中,旷视团队提出了 CPN 网络(Cascaded Pyramid Network)[2],获得 COCO 人体姿态识别的冠军。CPN 网络使用 ResNet 作为骨干网路,采用了类似特征金字塔的结构来生成高分辨的人体姿态关键点热点图。CPN 主干网路也是遵循从高分辨率特征到低分辨率特征的串行结构,最后通过跳连结构以及上采样操作,得到最终的高分辨率的热点特征图。
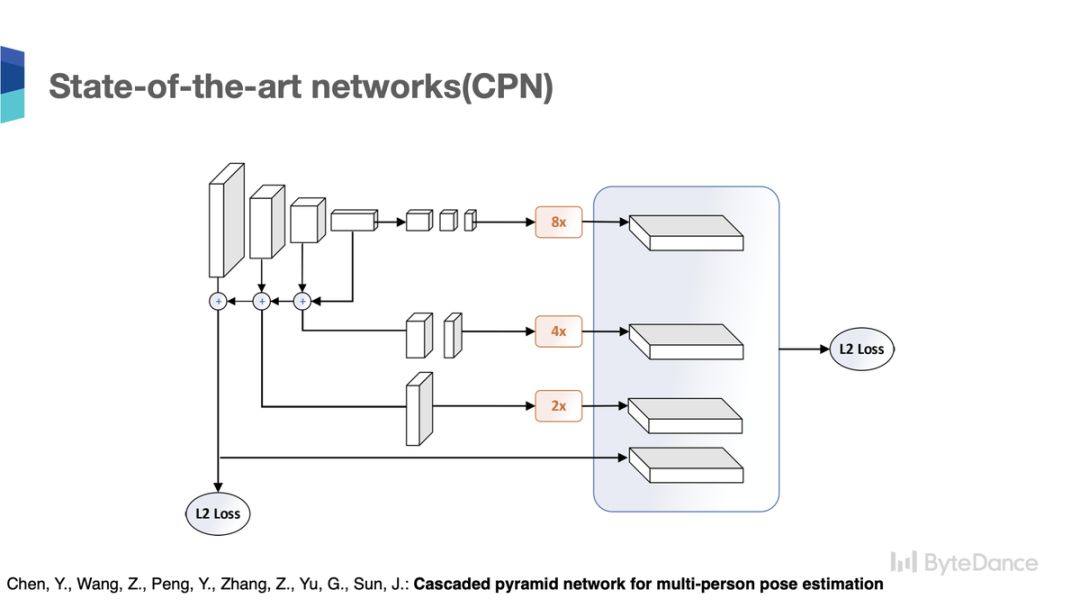
2018 ECCV 会议上,在人体姿态关键点检测任务中,微软亚洲研究院提出了一种通过三层级联的反卷积方法——Simple Baseline[3],来解码 ResNet 主干网路的低分辨率特征。这个方法很简单,但在人体关键点识别任务中取得了非常不错的成绩。Simple Baseline 的方法也遵循了从高分率到低分辨率学习,然后从低分辨率特征恢复高分辨特征的原则。
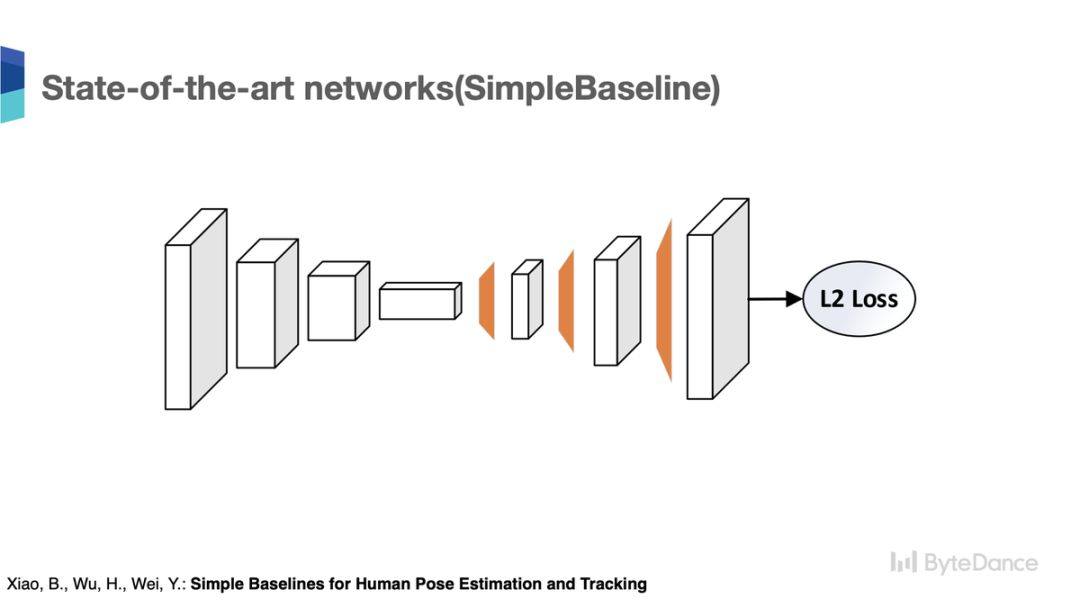
到这里总结一下,我们可以看出在人体关键点识别任务中,人体姿态识别的网路有以下几大特征:
(1)网络设计的结构都遵循从高分辨率到低分辨率的串行连接结构;
(2)高分辨率的人体姿态高分辨率热点图,都需要从低分辩的特征图恢复得到;
(3)通常,恢复的高分辨率特征图需要融合浅层的高分辨特征图。

为什么选择 HRNet?
我们认为在人体关键点检测任务中,是需要一个更强的高分辨表达的特征图,从技术路线上不应该只局限在从低分辨率特征来恢复或解码高分辨率特征这一种路线上,而应该直接通过网路来学习高分辨率的特征表达。
因此,我们选择了一种高分辨率表达的网路(High-Resolution Network,HRNet)[4]来做人体关键点检测任务。HRNet 在网路整个过程中维持或学习高分辨率的特征,渐进的增加低分辨率的的分支,并且通过特征交换模块,多次进行高分辨率和低分辨率的特征交换,从而学到足够丰富的高分辨率特征。
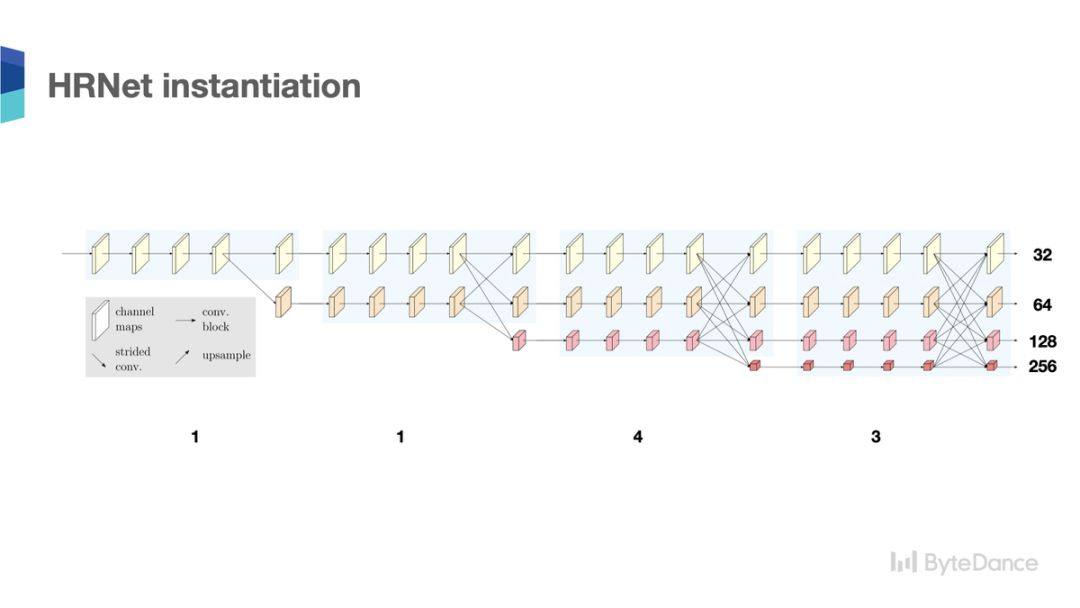
HRNet 的与众不同之处
通过对比我们可以看到 HRNet 和之前的网络具有很大的不同:
首先,HRNet 的高分辨率特征和低分辨率特征是并行连接。其次,HRNet 始终会学习一个高分辨率的特征表达。最后,HRNet 是通过多次的高分辨率特征和低分辨率特征的交换,来进一步增强高分辨率特征的学习。通过这种方式,HRNet 可以学到更强的高分辨率的特征表达。


HRNet 不仅在 LIP 人体姿态识别任务中取得了冠军的结果。在其他人体姿态识别的数据集上如 COCO 关键点检测任务,PoseTrack 人体姿态识别以及跟踪任务,MPII 人体字体识别任务中都得到了 State-of-the-art 的结果。
【附】References:
[1] Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. ECCV 2016.
[2] Chen, Y., Wang, Z., Peng, Y., Zhang, Z., Yu, G., Sun, J.: Cascaded pyramid network for multi-person pose estimation. CVPR 2018.
[3] Xiao, B., Wu, H., Wei, Y.: Simple Baselines for Human Pose Estimation and Tracking. ECCV 2018.
[4] Ke Sun, Bin Xiao, Dong Liu, Jingdong Wang: Deep High-Resolution Representation Learning for Human Pose Estimation. CVPR 2019.
(*本文为 AI科技大本营整理文章,转载请联系 1092722531)
◆
精彩推荐
◆
比写代码更重要的是抓住下一个技术风口,6月技术福利,BTA大牛带你一起探索未来的技术方向。机器学习、数据分析、自然语言处理、知识图谱等热门领域的大牛们都在关注什么?企业落地实践经验有哪些?扫码参与活动,限时免费获取。

推荐阅读:
